

Françoise Hardy likely never expected to be possessed by the spirit of Kellyanne Conway. ‘Alternative Face v1.1,’ uploaded to YouTube by the artist and programmer Mario Klingemann, combines a neural network called Pix2pix with facial-marker software to interpose Conway’s facial expressions from her now-infamous Meet the Press appearance onto the French singer-songwriter. While it was his intention to underscore the disturbing nature of the White House counselor’s statement by filtering it through Hardy’s girl-next-door persona, Klingemann didn’t want the technological implications of his experiment to be lost on his viewers either: “If you just put a little bit more processing power behind [fake news] you can create alternative facts that look real, like having another person saying something they never said.”
At its simplest, Pix2pix is a machine-learning tool that, by training itself on a database of hundreds of examples, can translate one style of image into another. If tasked with producing pictures of cats, Pix2pix will take even the most amateurish line drawing and transform it into a photorealistic rendition — sometimes spookily accurate, and sometimes just spooky. It can also achieve similar feats with video. By feeding Kellyanne Conway’s facial markers to a pix2pix database trained to recognize Françoise Hardy, Klingemann was able to map Conway’s expressions onto Hardy’s face frame by frame, and while his experiments did not yield perfect results — the background to the video is constantly flickering, and Hardy herself is victim to several jarring zooms — it’s nevertheless a startling demonstration of one of the most exciting breakthroughs in AI image research in years. If developed to their logical conclusion, tools like Pix2pix could well transform the way in which we approach graphic design, photography, and — as Klingemann has demonstrated — alternative facts.
For most of his artistic career, Klingemann’s works had traded on broader traditions within computer art that had been around for several decades, from experiments with code that recognized patterns within large data sets to generative algorithms that could produce weird and wonderful creations within pre-set limits. An artist whose primary goal has always been to build a program that would truly surprise him, he now compares that period to “10,000 bowls of oatmeal.” It wasn’t until the 2015 release of DeepDream, a computer vision program that accentuated subtle patterns it perceived in images to bizarre ends, that Klingemann began to realize the potential of neural networks in creating truly novel works of art. It was partly why he grew so excited about Pix2pix.
“I think the interesting part is that it allows you to have something like augmented creativity,” he says. “In a way, you start with just scribbling something, and then the network gives you a proposal, and then maybe that inspires you to change things. So it’s kind of this back and forth between you and the machine, but one where you are not only limited to your own imagination.”
Klingemann is an artist-in-residence at Google Arts & Culture, although he is clear that all the work he has done to push the capabilities of Pix2pix has been conducted on his own time. Having first used it to predict the next frame in movies — culminating in what the artist enthusiastically terms his “exploding baby head” — he quickly moved onto using it to enhance both still and moving images that, as the tool was trained for longer and longer periods, resulted in ever more accurate — if ghoulish — translations. At the end of January came a series of portraits resembling Victorian etchings, generated by a version of Pix2pix Klingemann trained on a huge data set of public domain images the British Library had uploaded to its Flickr account.
Watching throughout has been Phillip Isola, a postdoc in computer vision and machine learning at UC-Berkeley, and one of the original authors behind Pix2pix. “One of the most exciting things is that artists have started to get involved and use the code,” he says. “They, of course, did things that were far more creative than what we envisioned.”
Isola and his colleagues originally worked from the perspective of solving image-translation problems in graphics processing using Generative Adversarial Nets, or ‘GANs.’ GANs are, in fact, comprised of two neural nets locked in a guessing game with one another that Isola compares to the relationship between a detective and a forger. If a GAN has been built to produce pictures of cats, for example, the detective — who has been trained to recognize what a cat looks like from thousands of relevant images — challenges the forger to draw one from scratch. If the picture that is subsequently produced is not recognized as a cat, the detective rejects it and the forger has to start his work anew. Crucially, however, the forger is always learning from his mistakes. “That’s why it’s called an adversarial network,” says Isola. “They both get better until you get these forgeries, albeit generated images, which are quite realistic.”
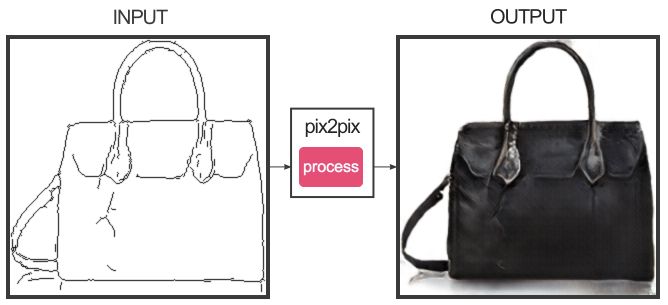
There’s a catch, however. While conventional GANs are capable of generating images almost spontaneously, they have to be trained on thousands of images to perform a task that has no obvious real-world applications. In their paper “Image-to-Image Translation with Conditional Adversarial Networks” Isola and his team were more interested in what would happen if the forger was allowed to work with an outline from the beginning. What they ended up with was a tool that took only hundreds of images with which to train and could create passable image translations with direct applications in graphic design.
“Suppose I want to render a room with a chair and a couch,” Isola explains. “I have to have a 3-D artist model that chair and that couch and it’s a really time-consuming process. These new things that we’re working on start to address that question, of how to get that chair there in the first place. [Now] you could just sketch it and [Pix2pix] can just finish it and make a nice-looking 3-D model or image out of that.”
Although GANs had been used to accomplish image translation before, they had usually been confined to applications in niche areas. By contrast, Pix2pix was much more flexible and open to experimentation. One of the first people to notice this was Gene Kogan, a programmer and co-author of the guide Machine Learning for Artists. Kogan was running a weeklong workshop at the Opendot Lab, in Milan, when he first heard about the paper. He immediately showed it to his students. “We started having a discussion about ideas for using it,” he explains. “At first I wanted to replicate the original research and remembered that you could easily get parallel sets of map and satellite imagery from Mapbox’s API, but the whole project kind of spun off very quickly.”
Over the next three days, Kogan and a team of coders created the “Invisible Cities” project, a demonstration of Pix2pix wherein three municipalities — Milan, Los Angeles, and Venice — were disguised as one another in satellite maps. Inspired by the novel of the same name by Italo Calvino, the team were also among the first coders to experiment with inputting hand-drawn sketches to see how the Pix2pix model would interpret their fantastical creations.
“With Pix2pix specifically, I thought Invisible Cities really helped to communicate the bigger picture of some of these research strands,” says Kogan. “There is a generality to many machine-learning methods that transcends a specific use case, and that can be lost on a casual viewer if they happen to see just one particular application. Doing these kinds of projects in the workshops can provide a way to experience this ‘aha!’ moment in a very visceral way.”
Perhaps the widest exposure of Pix2pix has been via the website Image to Image Demo, built by Isola’s friend and fellow programmer Christopher Hesse. In February the two met up to talk about the capabilities of the tool over coffee. Within a few weeks, Hesse had built a site that hosted three interactive versions of Pix2pix, something Isola hadn’t done. “When I wanted to do experiments or see what it would produce, I would run a big batch of images on a server and so forth and I wouldn’t see immediate feedback,” he recalls. “What I noticed once I could use this web app that Chris made was that I could learn so much more about the system pretty quickly.”
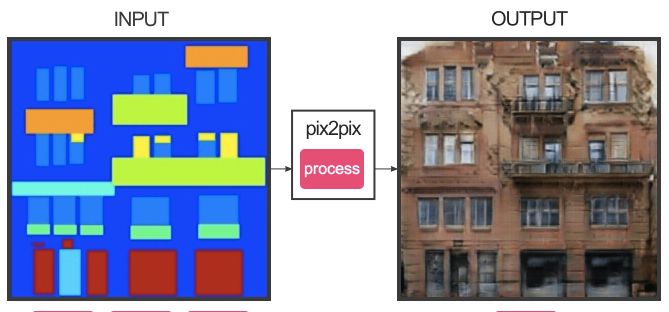
Predictably, it was Hesse’s cat generator that introduced Pix2pix to the rest of the internet, although more elaborate experiments with the tool have since emerged, including an attempted colorization of a short cartoon film and the interpolation of facades obtained from Google Street View onto 3-D block structures. “You can make it [and] have it do anything,” says Klingemann, although his and other users’ extensive exploration of the tool’s capabilities has led to their uncovering several flaws in the program. Training Pix2pix over a prolonged period and on too big a variety of things tends to eat up its internal memory, which can lead to generalizations in the image. Results are also better when the input and the output are geometrically aligned, which accounts not only for the good results seen in colorizing black-and-white footage but also the surplus in nightmare cats.
Isola himself is aware of these drawbacks, and actively welcomes feedback from users like Klingemann on Pix2pix’s GitHub page as interest in the tool continues to grow. The experience has even had an impact on the way he conducts his research, particularly in the importance of writing simple and accessible code. “It’s definitely really exciting, and it does make me think about what the right model for research is in this era,” says Isola. Careful empiricism has its place, he believes, but “[r]ather than necessarily going down every application kind of rabbit hole, which would also get caught up in research, it’s helpful to kind of crowdsource that process and … come up with new, creative ideas more quickly.”
Despite the current level of excitement surrounding Pix2pix, it isn’t hard to chart the probable trajectory of the tool. Although easier to train than other neural nets and with a diverse set of possible applications, the tool still requires hundreds of training images to work properly, therefore putting it out of range of a lot of programmers. This almost certainly means that Pix2pix will remain a cat-creating toy for most people, in the same way the DeepDream visualizations were initially treated as a disturbing insight into the minds of AIs before being dismissed as a passing fad. Even so, Isola thinks that that’s the wrong way to think about it. Instead, it’s better to conceive of Pix2pix as one rung on a long ladder stretching ever upward toward an unknown destination.
“I really love those fun demos and apps, but they will go away,” he says. “I think [they’re] best understood as just visualizations of the moment in research.” Imagining that, it’s a little easier to parse the artifacts and crackles in the images currently being generated into something more ambitious. After all, few expected the idea behind Niépce’s pewter plate to replace painting.



























